Network Architecture
Network
Polykey uses a combination of js-QUIC (in-house development by MatrxAI), js-RPC (in-house development by MatrxAI), and Kademlia DHT to establish and manage node-to-node connections in its network. This integration allows for efficient, secure, and reliable communication between nodes
+------------+ +------------+
| Bucket 0 | --> | Node IDs |
+------------+ +------------+
| Bucket 1 | --> | Node IDs |
+------------+ +------------+
| ... | | ... |
+------------+ +------------+
| Bucket N | --> | Node IDs |
+------------+ +------------+
Client JSON-RPC Server
| |
| --- Request ---> |
| |
| <--- Response -- |
| |
+--------+ QUIC +---------+
| Client | <------------> | Server |
| | | |
| | | |
+--------+ +---------+
Kademlia DHT Bucket Structure
Kademlia DHT (Distributed Hash Table) plays a crucial role in the Polykey network for node discovery and network topology management. It's a cornerstone of Polykey's decentralized architecture, allowing efficient and scalable peer-to-peer interactions. Here's a more detailed look at how Kademlia DHT functions within Polykey:
Expanded Explanation of Kademlia DHT in Polykey
Kademlia DHT (Distributed Hash Table) plays a crucial role in the Polykey network for node discovery and network topology management. It's a cornerstone of Polykey's decentralized architecture, allowing efficient and scalable peer-to-peer interactions. Here's a more detailed look at how Kademlia DHT functions within Polykey:
Basic Principles of Kademlia DHT
-
Node Identification: Each node in the Polykey network is assigned a unique identifier, commonly known as a Node ID. These IDs are typically large numbers or hashes, ensuring they are unique across the network.
-
Network Topology: Kademlia organizes nodes in a structured overlay network based on their Node IDs. This structure enables efficient routing of requests and responses.
-
Buckets and Distance: The Kademlia algorithm divides the network into buckets, each containing nodes at certain distances from a given node. The distance between two nodes is calculated using the XOR metric, which provides a consistent way to measure closeness in the network.
Kademlia DHT in Polykey
-
Bucket Structure: As shown in the ASCII diagram, each node maintains a series of buckets (K-buckets), each corresponding to a particular range of distances. Each bucket stores a limited number of Node IDs, typically those closest to the local node's ID within that bucket's range.
-
Node Discovery: When a Polykey node wants to find another node in the network (e.g., for establishing a connection or sharing data), it performs a lookup using the Kademlia DHT. The lookup process involves querying nodes in the closest bucket and progressively moving to farther buckets until the target node is found.
-
Network Maintenance: Nodes periodically perform maintenance tasks to keep their local DHT views up-to-date. This includes refreshing buckets (contacting nodes within each bucket to ensure they are still active) and handling node joins and departures.
-
Efficient Routing: The structured nature of Kademlia DHT allows Polykey nodes to route requests and responses efficiently. Each hop in the routing process gets closer to the target Node ID, significantly reducing the number of hops needed to reach the destination.
-
Scalability: Kademlia's design ensures that the number of steps required to find a node grows logarithmically with the number of nodes in the network. This scalability is crucial for Polykey as it allows the network to grow without a significant increase in lookup times.
Integration with QUIC and RPC
Kademlia DHT in Polykey works in tandem with QUIC and RPC:
-
Node Discovery for QUIC Connections: Once a target node's address is discovered through Kademlia, Polykey establishes a QUIC connection to that node. This connection is secure and efficient, benefiting from QUIC's low-latency and multiplexing capabilities.
-
RPC Over QUIC: After establishing the QUIC connection, Polykey uses its custom RPC protocol (js-RPC) to facilitate communication between nodes. This integration ensures that method calls and data exchanges are secure, reliable, and performant.
JSON-RPC Request-Response Flow
-
RPC is used in Polykey to facilitate communication between nodes. Once a QUIC connection is established, RPC calls are made over this connection. Polykey uses a custom RPC client that interfaces with the QUIC connection. This allows nodes to invoke methods on each other as if they were local function calls.
-
Polykey uses a custom implementation of RPC, our in-house js-rpc.
-
Polykey originally used GRPC but that came with its own set of challenges which included the need to proxy requests.
-
js-rpc was built from the ground up to be an all incomprehensible rpc system and supports a features not found in most rpc libraries, these include:
-
Ability to stream, as such js-rpc supports a variety of calls such as Streaming calls - Duplex Streaming, Client Streaming, Server streaming, Raw streams
-
js-rpc also supports unary calls, which form a cornerstone of most client calls.
Overview of calls and their handlers and callers supported by js-rpc
- Unary calls: In Unary calls, the client sends a single request to the server and receives a single response back, much like a regular async function call. Handler and caller
import type { JSONRPCParams, JSONRPCResult, JSONValue } from '@matrixai/rpc';
import { UnaryHandler } from '@matrixai/rpc';
class SquaredNumberUnary extends UnaryHandler<
ContainerType,
JSONRPCParams<{ value: number }>,
JSONRPCResult<{ value: number }>
> {
public handle = async (
input: JSONRPCParams<{ value: number }>,
cancel: (reason?: any) => void,
meta: Record<string, JSONValue> | undefined,
ctx: ContextTimed,
): Promise<JSONRPCResult<{ value: number }>> => {
return input.value ** 2;
};
}
import type { HandlerTypes } from '@matrixai/rpc';
import { UnaryCaller } from '@matrixai/rpc';
type CallerTypes = HandlerTypes<SquaredNumberUnary>;
const squaredNumber = new UnaryCaller<
CallerTypes['input'],
CallerTypes['output']
>();
- Client streaming: In Client Streaming calls, the client can write multiple messages to a single stream, while the server reads from that stream and then returns a single response. This pattern is useful when the client needs to send a sequence of data to the server, after which the server processes the data and replies with a single result. This pattern is good for scenarios like file uploads.
import type { JSONRPCParams, JSONRPCResult, JSONValue } from '@matrixai/rpc';
import { ClientHandler } from '@matrixai/rpc';
class AccumulateClient extends ClientHandler<
ContainerType,
JSONRPCParams<{ value: number }>,
JSONRPCResult<{ value: number }>
> {
public handle = async (
input: AsyncIterableIterator<JSONRPCParams<{ value: number }>>,
cancel: (reason?: any) => void,
meta: Record<string, JSONValue> | undefined,
ctx: ContextTimed,
): Promise<JSONRPCResult<{ value: number }>> => {
let acc = 0;
for await (const number of input) {
acc += number.value;
}
return { value: acc };
};
}
import type { HandlerTypes } from '@matrixai/rpc';
import { ClientCaller } from '@matrixai/rpc';
type CallerTypes = HandlerTypes<AccumulateClient>;
const accumulate = new ClientCaller<
CallerTypes['input'],
CallerTypes['output']
>();
- Sever streaming : In Server Streaming calls, the client sends a single request and receives multiple responses in a read-only stream from the server. The server can keep pushing messages as long as it needs, allowing real-time updates from the server to the client. This is useful for things like monitoring, where the server needs to update the client in real-time based on events or data changes. In this example, the client sends a number and the server responds with the squares of all numbers up to that number.
import type { JSONRPCParams, JSONRPCResult, JSONValue } from '@matrixai/rpc';
import { ServerHandler } from '@matrixai/rpc';
class CountServer extends ServerHandler<
ContainerType,
JSONRPCParams<{ value: number }>,
JSONRPCResult<{ value: number }>
> {
public handle = async function* (
input: JSONRPCParams<{ value: number }>,
cancel: (reason?: any) => void,
meta: Record<string, JSONValue> | undefined,
ctx: ContextTimed,
): AsyncIterableIterator<JSONRPCResult<{ value: number }>> {
for (let i = input.number; i < input.number + 5; i++) {
yield { value: i };
}
};
}
import type { HandlerTypes } from '@matrixai/rpc';
import { ServerCaller } from '@matrixai/rpc';
type CallerTypes = HandlerTypes<CountServer>;
const count = new ServerCaller<CallerTypes['input'], CallerTypes['output']>();
- Duplex streaming: A Duplex Stream enables both the client and the server to read and write messages in their respective streams independently of each other. Both parties can read and write multiple messages in any order. It's useful in scenarios that require ongoing communication in both directions, like chat applications.
import type { JSONRPCParams, JSONRPCResult, JSONValue } from '@matrixai/rpc';
import { DuplexHandler } from '@matrixai/rpc';
class EchoDuplex extends DuplexHandler<
ContainerType,
JSONRPCParams,
JSONRPCResult
> {
public handle = async function* (
input: AsyncIterableIterator<JSONRPCParams<{ value: number }>>, // This is a generator.
cancel: (reason?: any) => void,
meta: Record<string, JSONValue> | undefined,
ctx: ContextTimed,
): AsyncIterableIterator<JSONRPCResult<{ value: number }>> {
for await (const incomingData of input) {
yield incomingData;
}
};
}
import type { HandlerTypes } from '@matrixai/rpc';
import { ServerCaller } from '@matrixai/rpc';
type CallerTypes = HandlerTypes<EchoDuplex>;
const echo = new ServerCaller<CallerTypes['input'], CallerTypes['output']>();
- Raw streaming: Raw Streams are designed for low-level handling of RPC calls, enabling granular control over data streaming. Unlike other patterns, Raw Streams allow both the server and client to work directly with raw data, providing a more flexible yet complex way to handle communications. This is especially useful when the RPC protocol itself needs customization or when handling different types of data streams within the same connection.
import type { JSONRPCRequest, JSONValue } from '@matrixai/rpc';
import { RawHandler } from '@matrixai/rpc';
class FactorialRaw extends RawHandler<ContainerType> {
public handle = async (
[request, inputStream]: [JSONRPCRequest, ReadableStream<Uint8Array>],
cancel: (reason?: any) => void,
meta: Record<string, JSONValue> | undefined,
ctx: ContextTimed,
): Promise<[JSONValue, ReadableStream<Uint8Array>]> => {
const { readable, writable } = new TransformStream<
Uint8Array,
Uint8Array
>();
(async () => {
function factorialOf(n: number): number {
return n === 0 ? 1 : n * factorialOf(n - 1);
}
const reader = inputStream.getReader();
const writer = writable.getWriter();
while (true) {
const { done, value } = await reader.read();
if (done) {
break;
}
const num = parseInt(new TextDecoder().decode(value), 10);
const factorial = factorialOf(num).toString();
const outputBuffer = new TextEncoder().encode(factorial);
writer.write(outputBuffer);
}
writer.close();
})();
return [
'Starting factorial computation',
readable as ReadableStream<Uint8Array>,
];
};
}
import { RawCaller } from '@matrixai/rpc';
const factorial = new RawCaller();
Timeouts in js-rpc
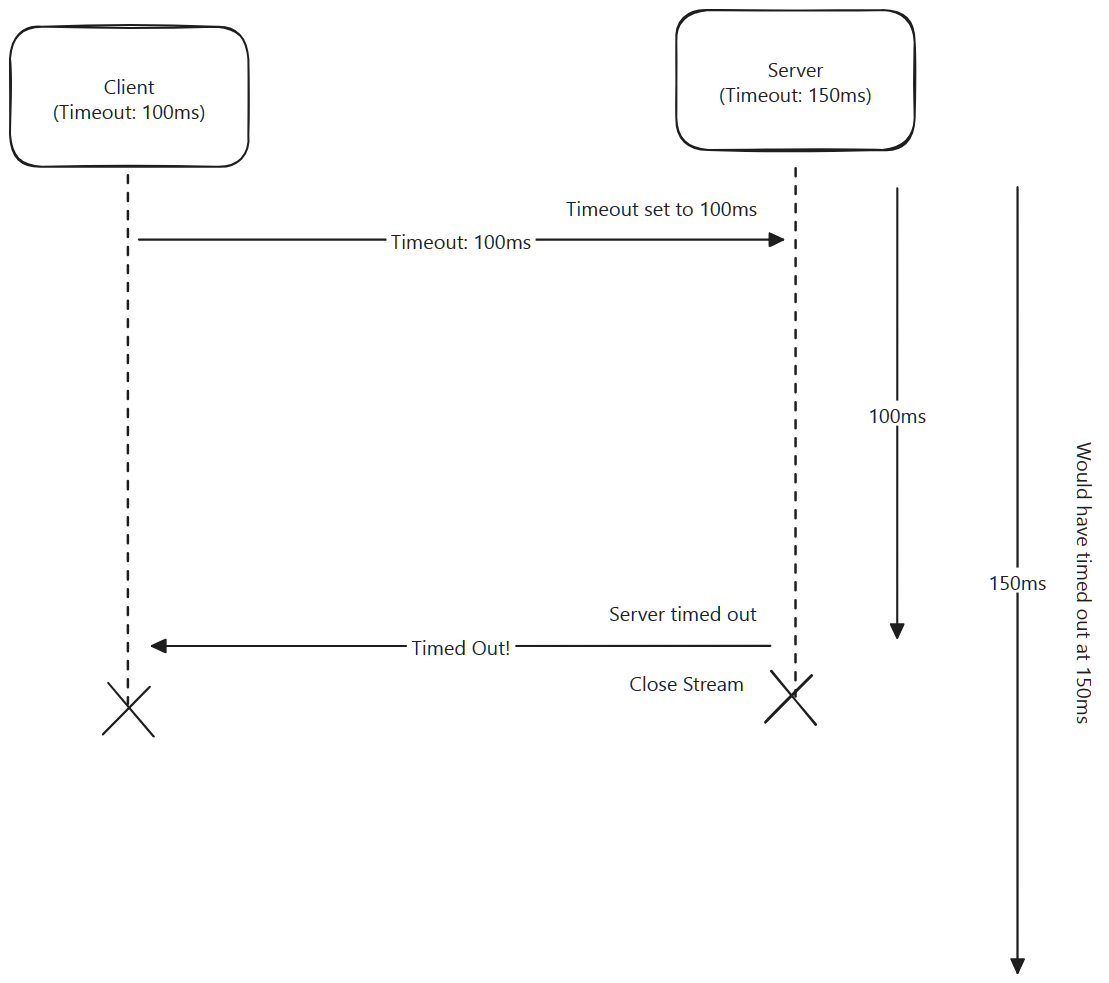
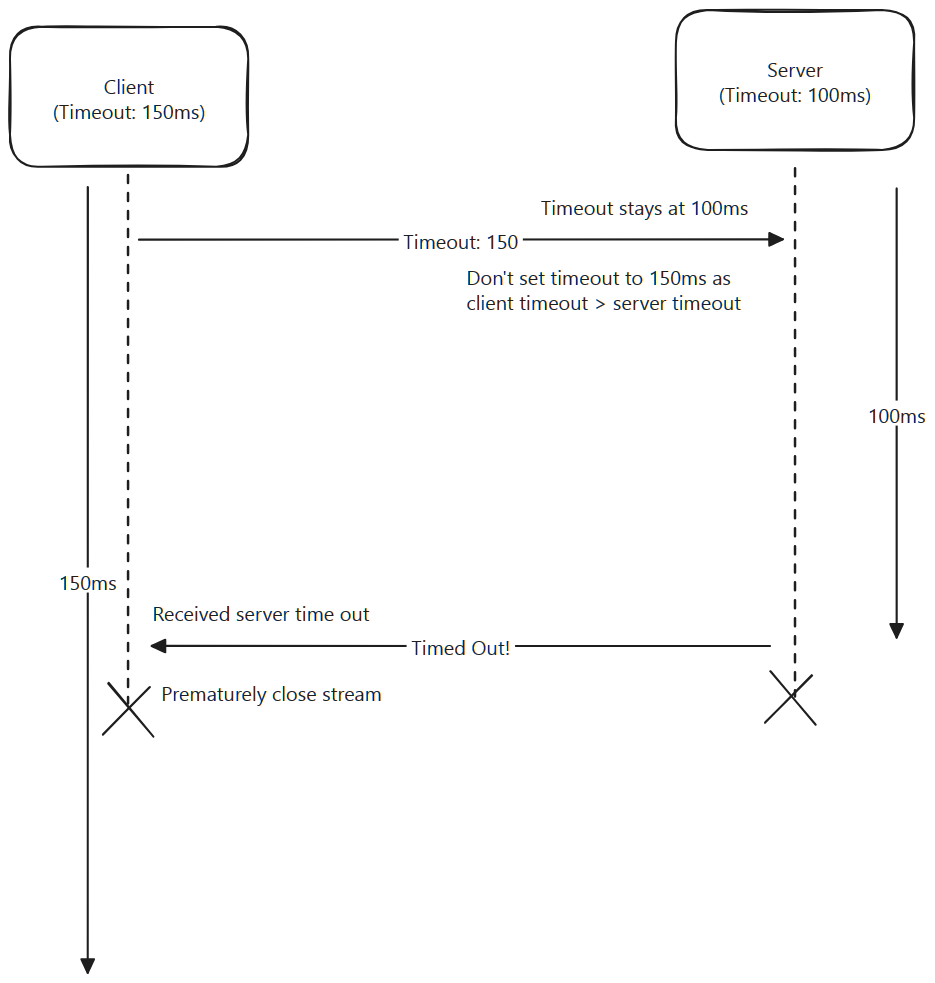
-
The timeoutMiddleware is enabled by default, and uses the .metadata.timeout property on a JSON-RPC request object for the client to send it's timeout.
-
A timeoutTime can be passed both to the constructors of RPCServer and RPCClient. This is the default timeoutTime for all callers/handlers.
-
In the case of RPCServer, a timeout can be specified when extending any Handler class. This will override the default timeoutTime set on RPCServer for that handler only.
-
In the case of RPCClient, a ctx with the property timer can be supplied with a Timer instance or number when making making an RPC call. This will override the default timeoutTime set on RPCClient for that call only.
-
However, it's important to note that any of these timeouts may ultimately be overridden by the shortest timeout of the server and client combined using the timeout middleware above.
QUIC Connection Overview
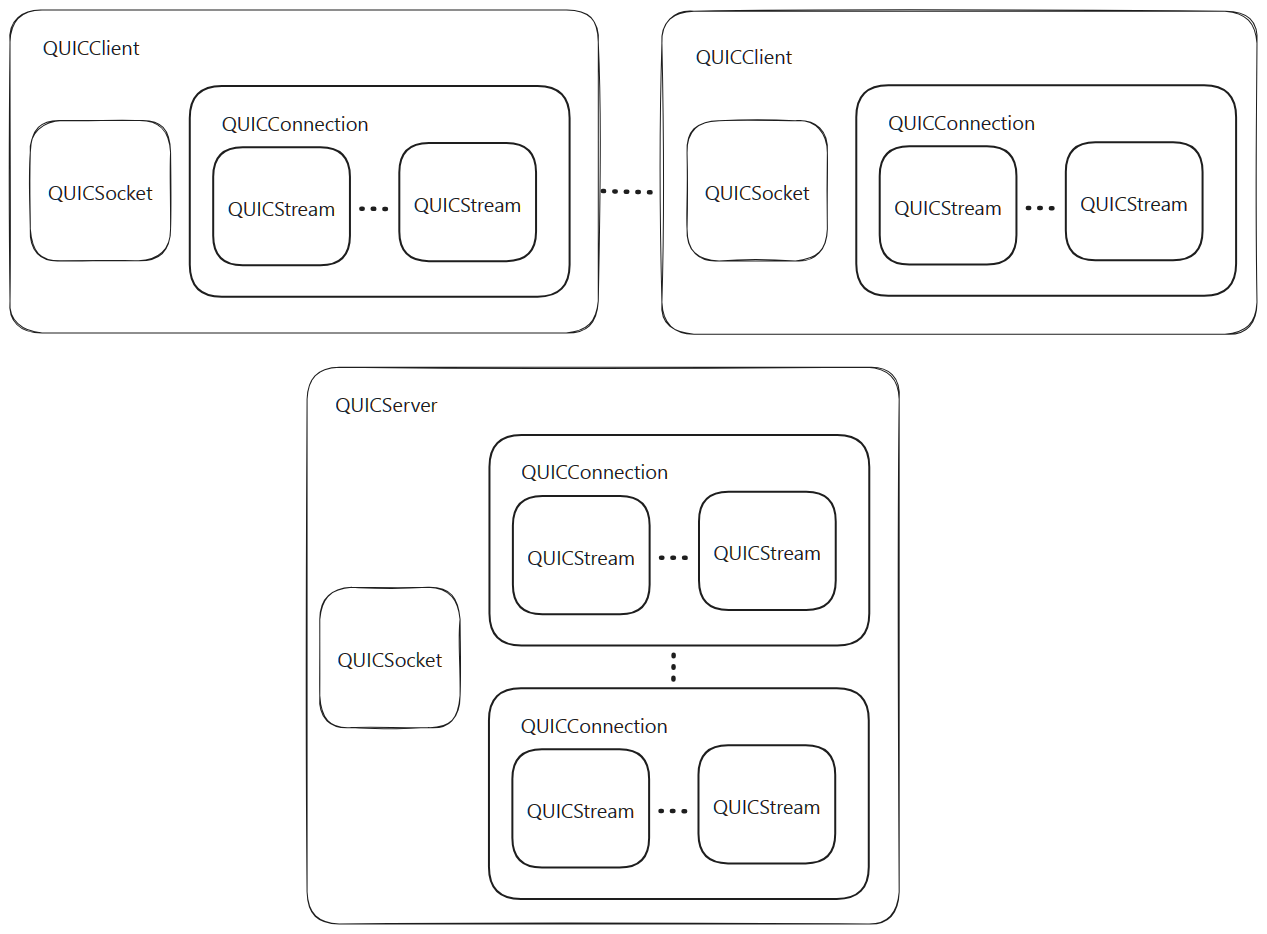
-
js-quic is a Matrix AI built QUIC library for JS applications.
-
This is built on top of Cloudflare's quiche library.
-
This library focuses only on the QUIC protocol. It does not support HTTP3. You can build HTTP3 on top of this.
-
It is possible to structure the QUIC system in the encapsulated way or the injected way.
-
When using the encapsulated way, the QUICSocket is separated between client and server.
-
When using the injected way, the QUICSocket is shared between client and server.
- If you are building a peer to peer network, you must use the injected way.
- This is the only way to ensure that hole-punching works because both the client and server for any given peer must share the same UDP socket and thus share the QUICSocket.
- When done in this way, the QUICSocket lifecycle is managed outside of both the QUICClient and QUICServer.
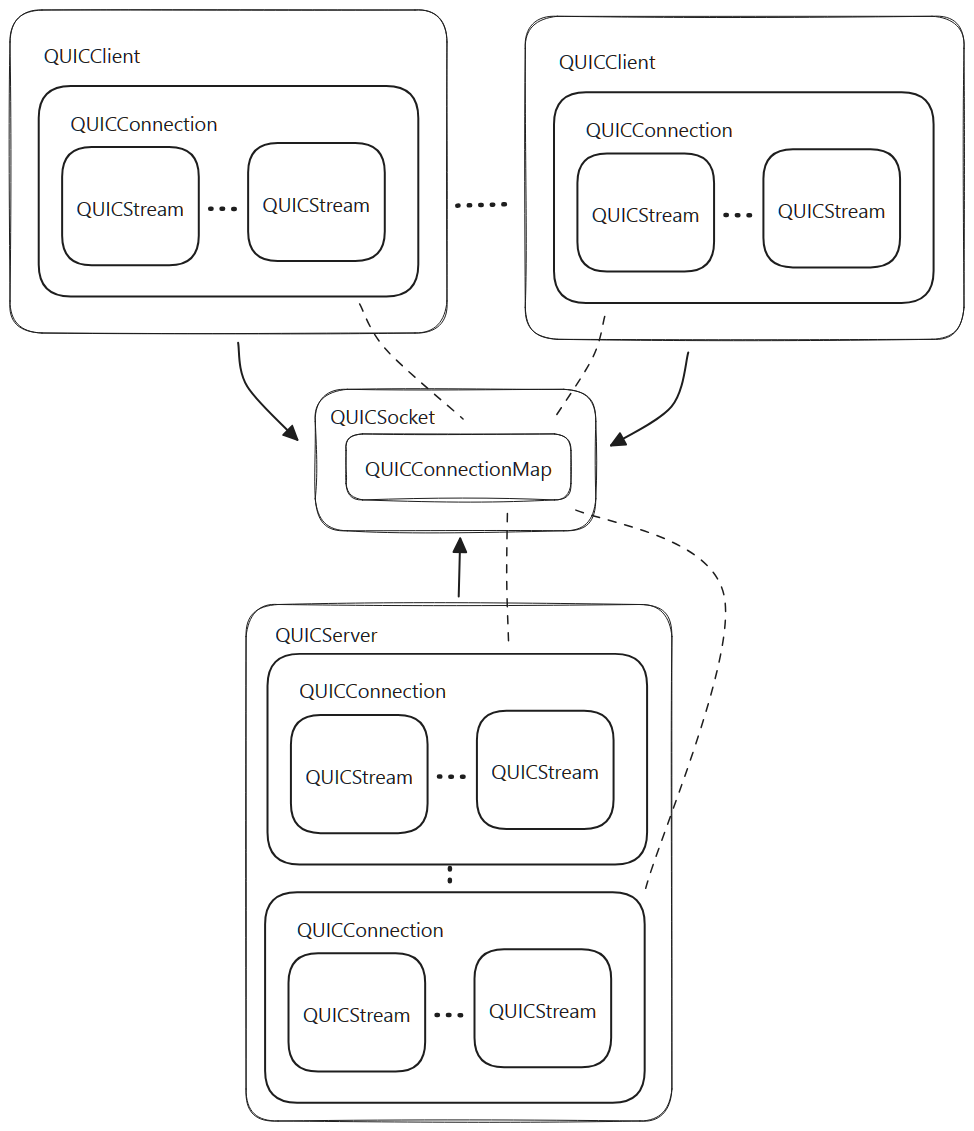
- This also means both QUICClient and QUICServer must share the same connection map.
- In order to allow the QUICSocket to dispatch data into the correct connection, the connection map is constructed in the QUICSocket, however setting and unsetting connections is managed by QUICClient and QUICServer.
Dataflow in QUIC
- The data flow of the QUIC system is a bidirectional graph.
- Data received from the outside world is received on the UDP socket.
- It is parsed and then dispatched to each QUICConnection.
- Each connection further parses the data and then dispatches to the QUICStream.
- Each QUICStream presents the data on the ReadableStream interface, which can be read by a caller.
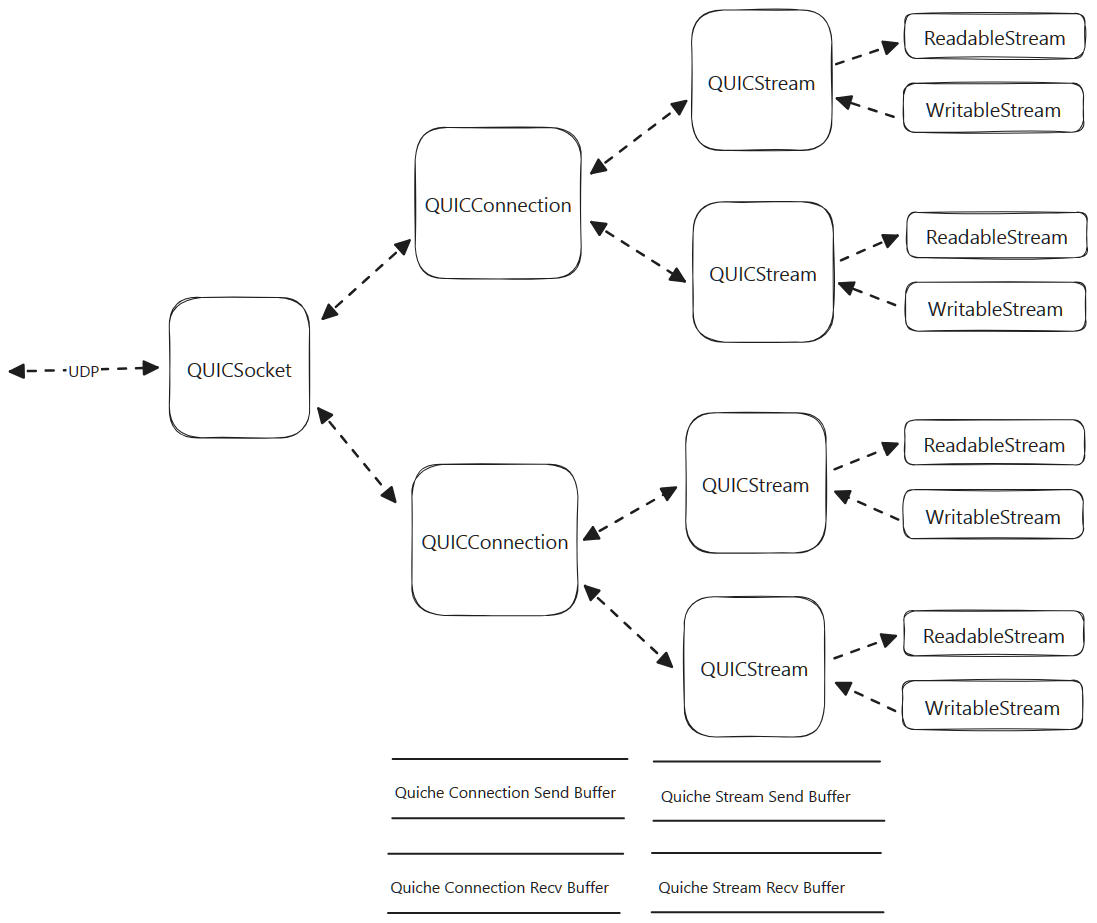
- Data sent to the outside world is written to a WritableStream interface of a QUICStream.
- This data is buffered up in the underlying Quiche stream.
- A send procedure is triggered on the associated QUICConnection which takes all the buffered data to be sent for that connection, and sends it to the QUICSocket, which then sends it to the underlying UDP socket.
Data Buffering
- Buffering occurs at the connection level and at the stream level.
- Each connection has a global buffer for all streams, and each stream has its own buffer.
- Note that connection buffering and stream buffering all occur within the Quiche library.
- The web streams ReadableStream and WritableStream do not do any buffering at all.
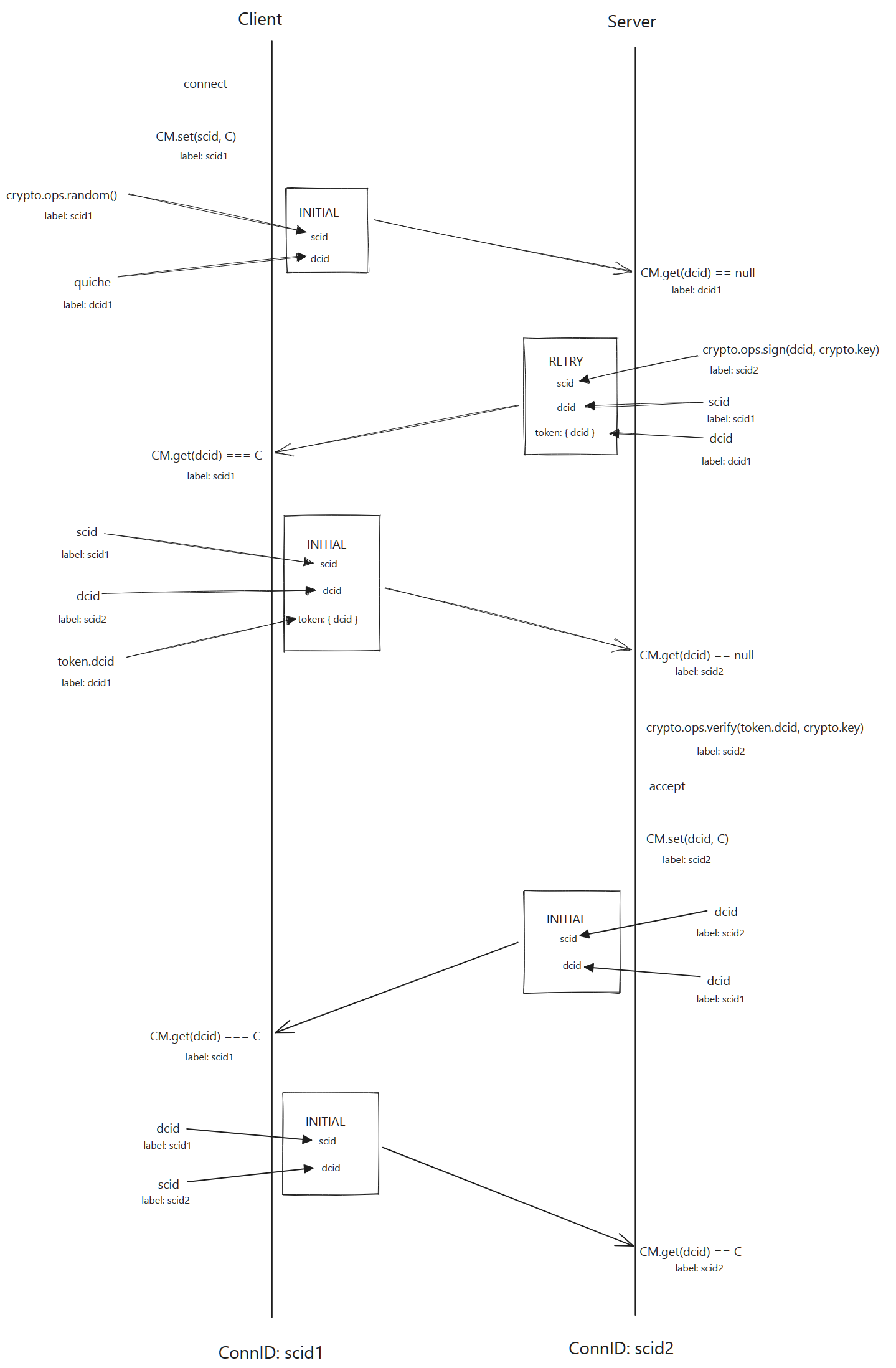
Connection Negotiation
The connection negotiation process involves several exchanges of QUIC packets before the QUICConnection is constructed.
The primary reason to do this is for both sides to determine their respective connection IDs.
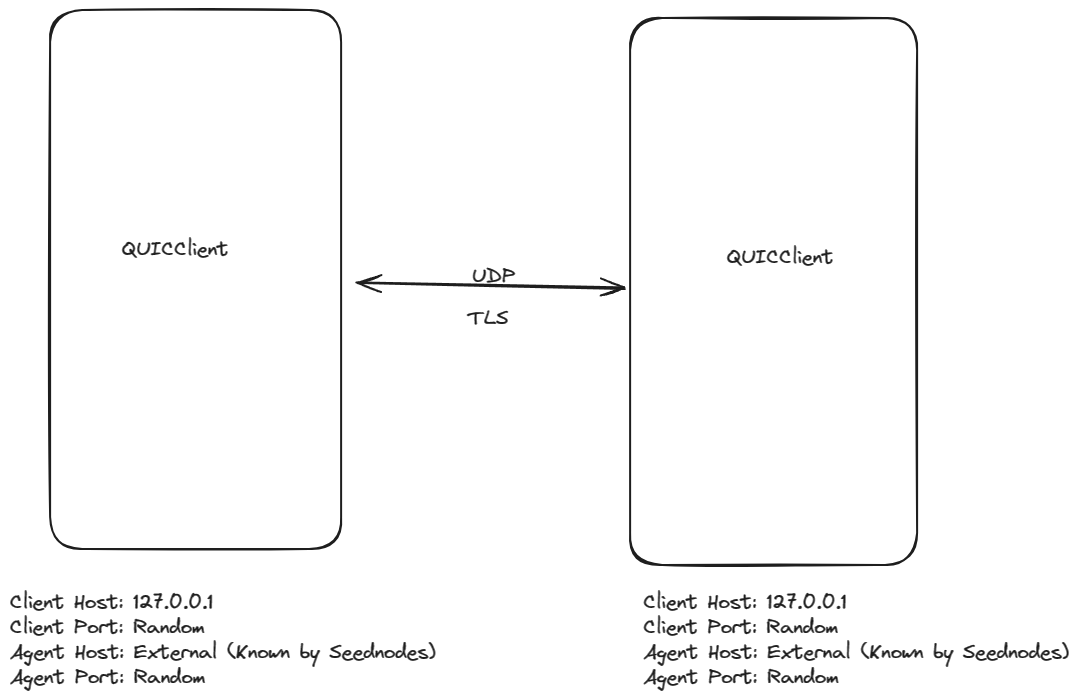
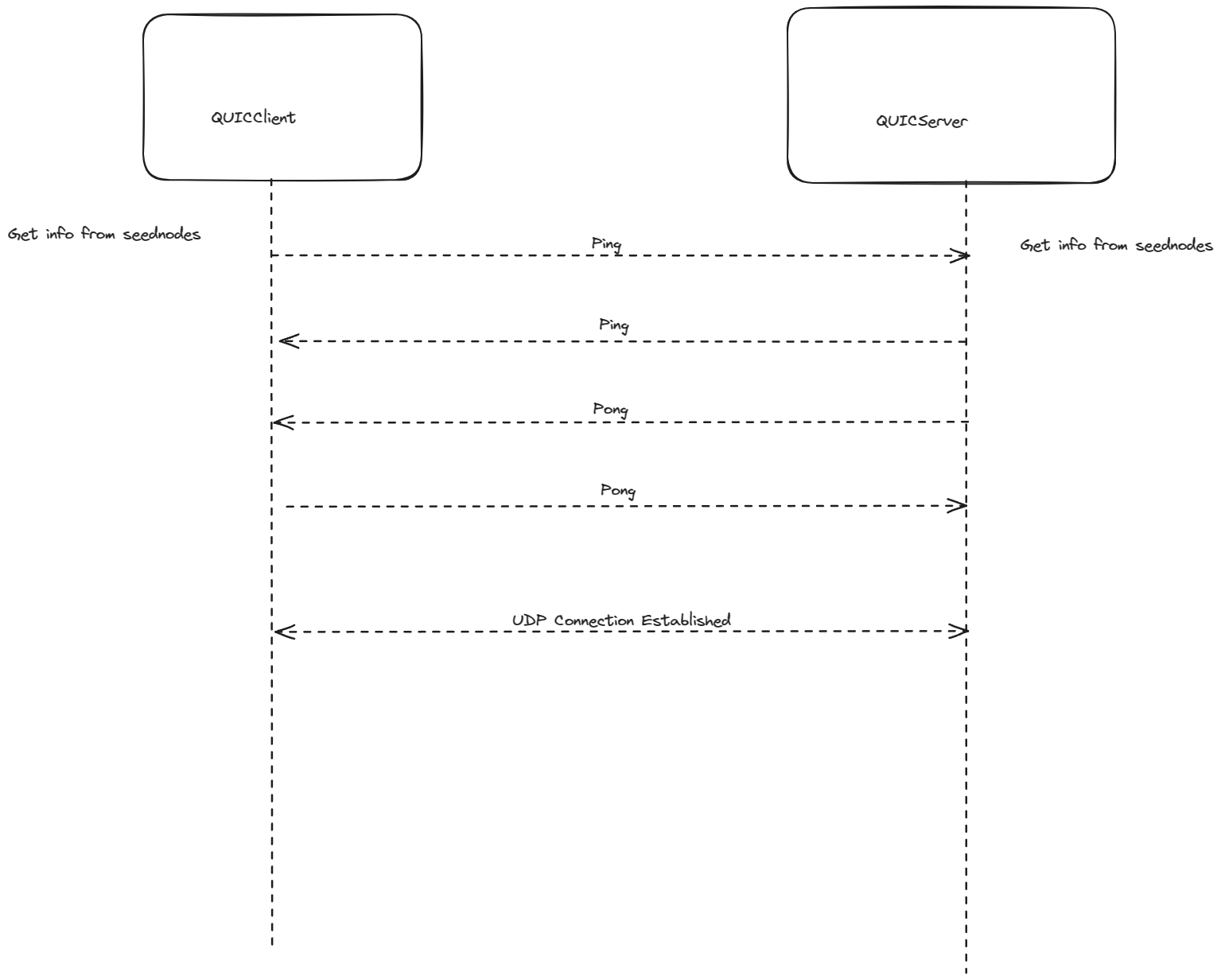
NAT Holepunching within Polykey Network
Polykey utilizes a combination of Kademlia DHT, js-QUIC, and js-RPC to establish and manage its network connections. To facilitate direct peer communication even when behind NATs, Polykey implements a custom NAT holepunching technique.
Here's how it works:
- Client Discovery:
- Each node maintains a Kademlia bucket structure, facilitating efficient node discovery and network topology management.
- When a client desires to connect to another node, it uses the Kademlia DHT to lookup the target node's ID.
- This lookup process returns the target node's IP address and port number.
- Server Binding:
- Both the client and the target node initiate a QUIC connection establishment process towards a pre-defined server (e.g., a TURN server).
- This server acts as a rendezvous point and facilitates the exchange of necessary information for NAT traversal.
- During the QUIC connection establishment, each node sends its local IP address, port number, and a unique identifier to the server.
- Binding Information Exchange:
- Once both the client and the target node have established QUIC connections with the server, they send their respective binding information (local IP, port, and identifier) to each other via the server.
- This exchange utilizes a custom RPC protocol over the QUIC connection, specifically js-RPC developed by MatrixAI.
- Direct Connection Attempt:
- Using the received binding information, both the client and the target node attempt to directly connect to each other using QUIC.
- This direct connection bypasses the TURN server and allows direct peer-to-peer communication.
- Holepunching Success:
- If the direct connection attempt is successful, a NAT hole is punched, enabling bi-directional communication between the client and the target node.
- Subsequent data exchange can occur directly over the QUIC connection without the need for the TURN server.
- Note: This is a simplified overview of the Polykey NAT holepunching process. The actual implementation may involve additional steps and optimization techniques for different scenarios.
Additional Considerations:
Symmetric vs. Asymmetric NAT:
- Polykey's holepunching technique works for both symmetric and asymmetric NATs.
- For symmetric NATs, a second round of connection establishment might be necessary to complete the holepunching process.
Firewall Rules:
- Depending on the firewall configuration, additional rules might be required to allow incoming QUIC connections on specific ports.
Benefits of Polykey's NAT Holepunching:
-
Direct Peer-to-peer Communication: Enables efficient and low-latency communication between nodes.
-
Reduced Reliance on Central Servers: Minimizes dependence on centralized TURN servers, improving network scalability and resilience.
-
Flexibility and Security: Utilizes QUIC and js-RPC for secure and reliable communication.
-
This custom NAT holepunching technique allows Polykey to effectively establish and manage direct connections between nodes in its network, even when behind NATs, contributing to a robust and efficient decentralized network architecture.